服务的性能概述、优化及测试工具
一、服务性能及优化
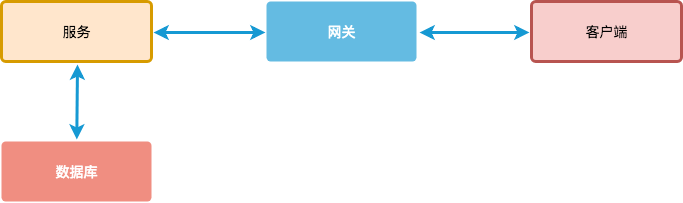
一般服务器的组成结构主要包括以下5部分:客户端、网关、服务、数据库以及各个系统之间的宽带。
1、客户端
1.1. 减少请求频率和次数
- 配置数据做本地缓存,避免多次请求。对实时性要求高的缓存数据,采用增量更新。
- 提交修改前作检查,避免没有修改内容,也提交到服务器。
- 业务非必须的情况下,避免并发请求,采用懒加载。(如:多页数据分别加载、图片显示时才加载等)
1.2. 减少带宽占用
- 请求数据进行压缩(json 压缩),减少带宽占用。
2、网关
采用高性能网关(nginx 等)
启用数据压缩(如果服务端没有实现)
分流,限流
3、服务
3.1. 服务架构
单服务性能瓶颈后,可以做集群,也可以做微服务。
- 单服务:如果能满足正常业务,可以不调整。
- 集群:单服务不能满足时,可采用多个单服务的集群。实现初级扩展,可以快速提高服务处理能力。
- 微服务:需要服务拆分,可能涉及夸数据库事务处理等。
3.2. 服务性能
提高单个服务的性能
- 基础框架:JAVA 的springboot,go等
- Web应用服务器:tomcat、undertow 等
- 各应用组件的选择:json、日志等
3.3. 缓存能力
1、热点数据做缓存,利用缓存、缓解数据库压力,提高性能
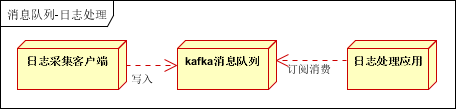
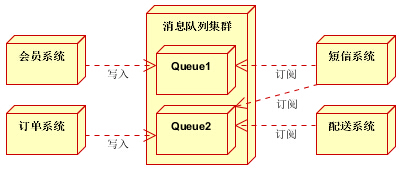
3.4. 异步消息
1、并发高的业务,可采用消息队列缓冲;
2、与主体逻辑不相关的业务,可以采用消息进行通知。(如邮件、短信等)
4、数据库
4.1. 数据库性能匹配
设计的数据库类型,id 等,需要符合数据引擎的特性,提高性能。
- MySql的 InnoDb最好采用自增 id
- 使用索引,提高查询效率,索引使用遵循原则
4.2. 数据库集群
- 对于读性能要求高的业务,可以采用读写分离
- 对于数据量大的业务,可以考虑分库分表
5、带宽
- 网关-服务-数据库 尽量在同一内网中。
- 提高客户端-网关的宽带。
- 分离对象业务:将对象数据,存储于专门的对象服务器。
二、优化方案
1、对象资源内容
对于图片、视频、音频等资源,不应该放在服务中。占用服务带宽和CPU资源。
对象应该存放在专门的对象服务器中。
1、七牛对象服务。
2、自建服务器。
2、热点资源缓存
做缓存,一般可采用 redis
1)用户数据和认证数据 token
2)接口验证数据(公司信息,项目信息),配置数据。
3)最近都热点数据(日报、组织架构等),设置过期时间
4)持久化数据(验证通过的单子,数据永远不会变),消息(生成就不会变)。设置过期时间
5)树结构设计 idPath(路径:|1.2.3),可以按照 like 搜索所有子节点。更新修改的次数比较多。
3、提高硬件配置
CPU、内存、宽带
4、jvm 优化
工作日志:
Xms Xmx 可设置成一样,避免内容波动。16G设置为8G。
Xmn 新生代:2G
-Xss128k 线程大小
-XX:newRatio = 2;
1)4调整到2,响应时间快,老年代的减少,由缓存弥补。
2)吞吐量大,老年代大。
整合服务:
Xms Xmx 根据业务大小设置。
5、mysql
1)设计原则
索引,最左原则。最多没有超过3个。消息,架构,日志。
like 最好不要用左匹配,不能使用到索引
id 自增,聚镞 不适合 uuid
2)连接池
1)durid 阿里开源,性能好,有监控
2)HikariCP 速度比 durid 快,小巧
6、传输格式
一般采用 REST 接口,数据格式为json
1)json 压缩,去掉换行,空格等;
2)容器压缩,tomcat 进行压缩。
3)nginx 进行 gzip 压缩。
如果对数据大小要求更高,可采用 gRPC。
三、性能测试工具
性能测试工具
1、wrk
wrk是轻量化的http性能测试工具,采用线程+网络异步IO模型,网络异步IO可以使得系统使用很少的线程模拟大量的网络连接以增大并发量、提高压力。
- 操作简单、易于使用
- 只支持简单测试、只支持单机测试
- 适用于初期测试,评判系统的 QPS 水平
使用
1 | ./wrk -t 8 -c 1000 -d 10s http://www.baidu.com |
- -t(–thread) 需要模拟的线程数;不宜过大,
- -c(connection) 需要模拟的连接数;
- –timeout 超时的时间;-d(–duration) 测试的持续时间
2、jmeter
jmeter同样采用线程并发机制,但其主要依靠增加线程数提高并发量,当单机模拟数以千计的并发用户时,对于CPU和内存的消耗比较大。与上述wrk相比,jmeter本身具有以下优点和缺点:
优点
①界面可视化操作,可以使用录制脚本方式对较为复杂的用户流建模,还可以创建断言来验证测试行为是否通过;
②表格、图形、结果树等多类可视化数据分析和报告输出,举例如下;
③支持http、ftp、tcp等多种协议类型测试;
④支持分布式压力测试,但对于上万的用户并发测试需要多台测试机支持,资源要求比较大;
⑤可以用于测试固定吞吐量下的系统性能,例如在100QPS(QPS:每秒查询率)下系统的响应时间和资源消耗;
缺点
jmeter的GUI模式消耗资源较大,当需要测试高负载时,需要先使用GUI工具来生成XML测试计划,然后在非GUI模式下导入测试计划运行测试,并且关闭不需要的侦听器(收集数据与展示测量的组件),因为侦听器也会消耗掉本用于生成负载的大量资源。测试结束后后,需要将原始结果数据导入GUI以才能查看结果。
3、locust
locust是一个的简单易用的分布式负载测试工具,主要用来对网站进行负载压力测试。locust使用python语言开发,测试资源消耗远远小于java语言开发的jmeter。且其支持分布式部署测试,能够轻松模拟百万级用户并发测试。
与jmeter和wrk相比,locust具有以下优缺点:
优点
①不同与wrk和jmeter使用线程数提高并发量,locust借助于协程实现对用户的模拟,相同物理资源(机器cpu、内存等)配置下locust能支持的并发用户数相比jmeter可以提升一个数量级;
②相比wrk对复杂场景测试的捉襟见肘和jmeter需要界面点击录制复杂场景的麻烦,locust只需用户使用python编写用户场景完成测试;
③不同与jmeter复杂的用户使用界面,locust的界面干净整洁,可以实时显示测试的相关细节(如发送请求数、失败数和当前发送请求速度等);
④locust虽然是面向web应用测试的,但是它可以用来测试几乎所有系统。给locust编写一个客户端,可以满足你所有的测试要求;
缺点
同wrk一样,locust测试结果输出不如jmeter的测试结果展示类型多;